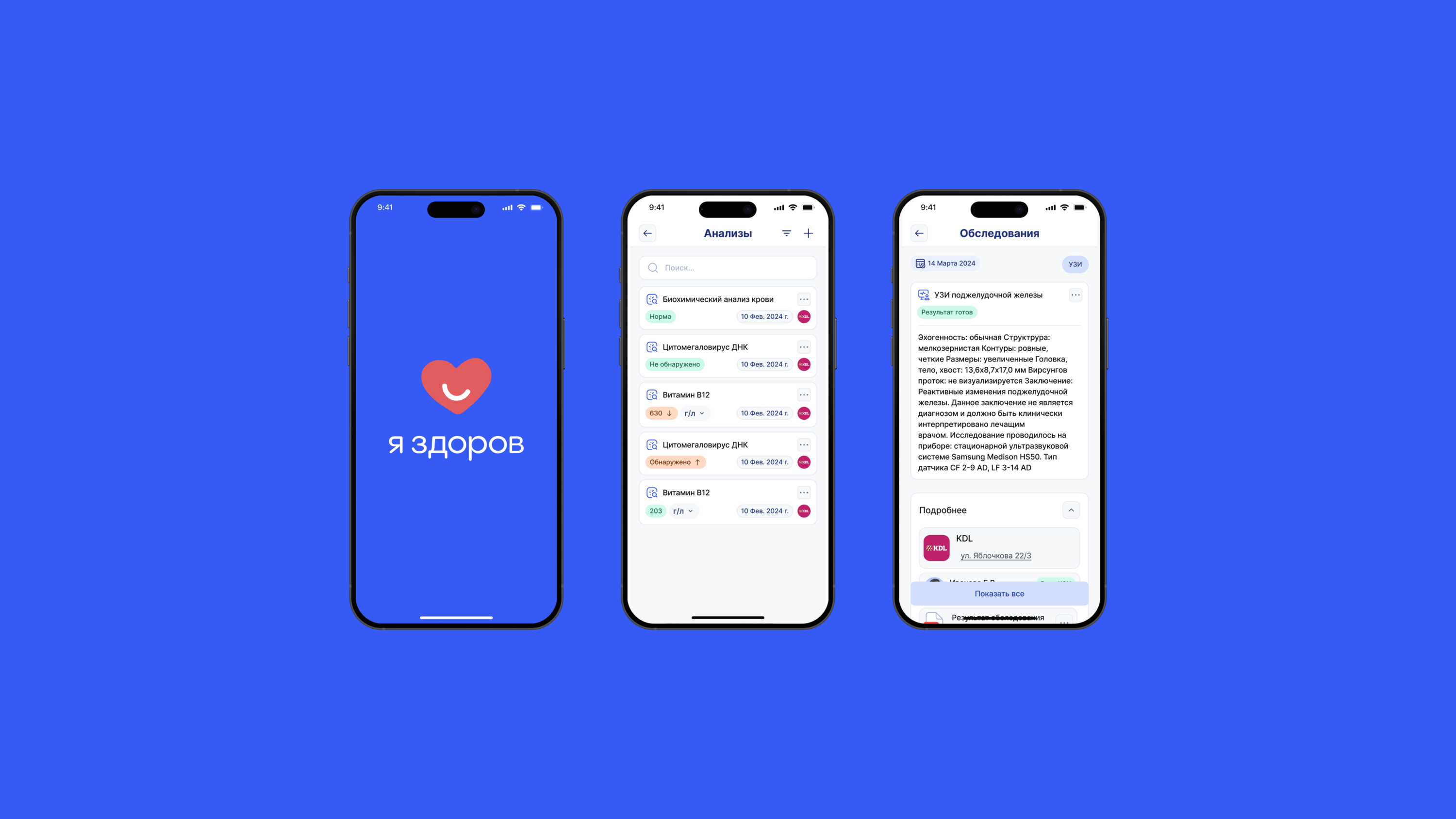
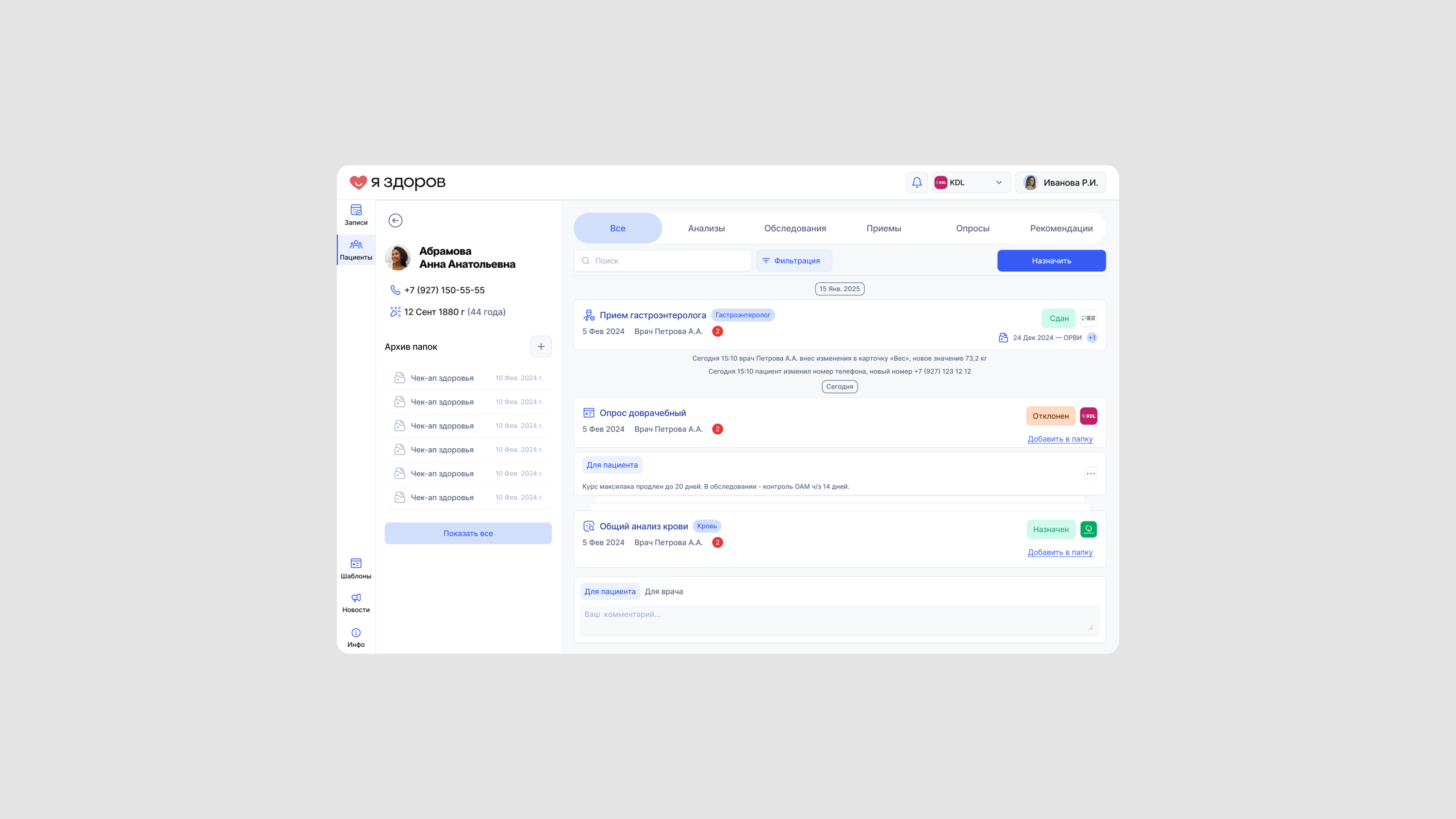
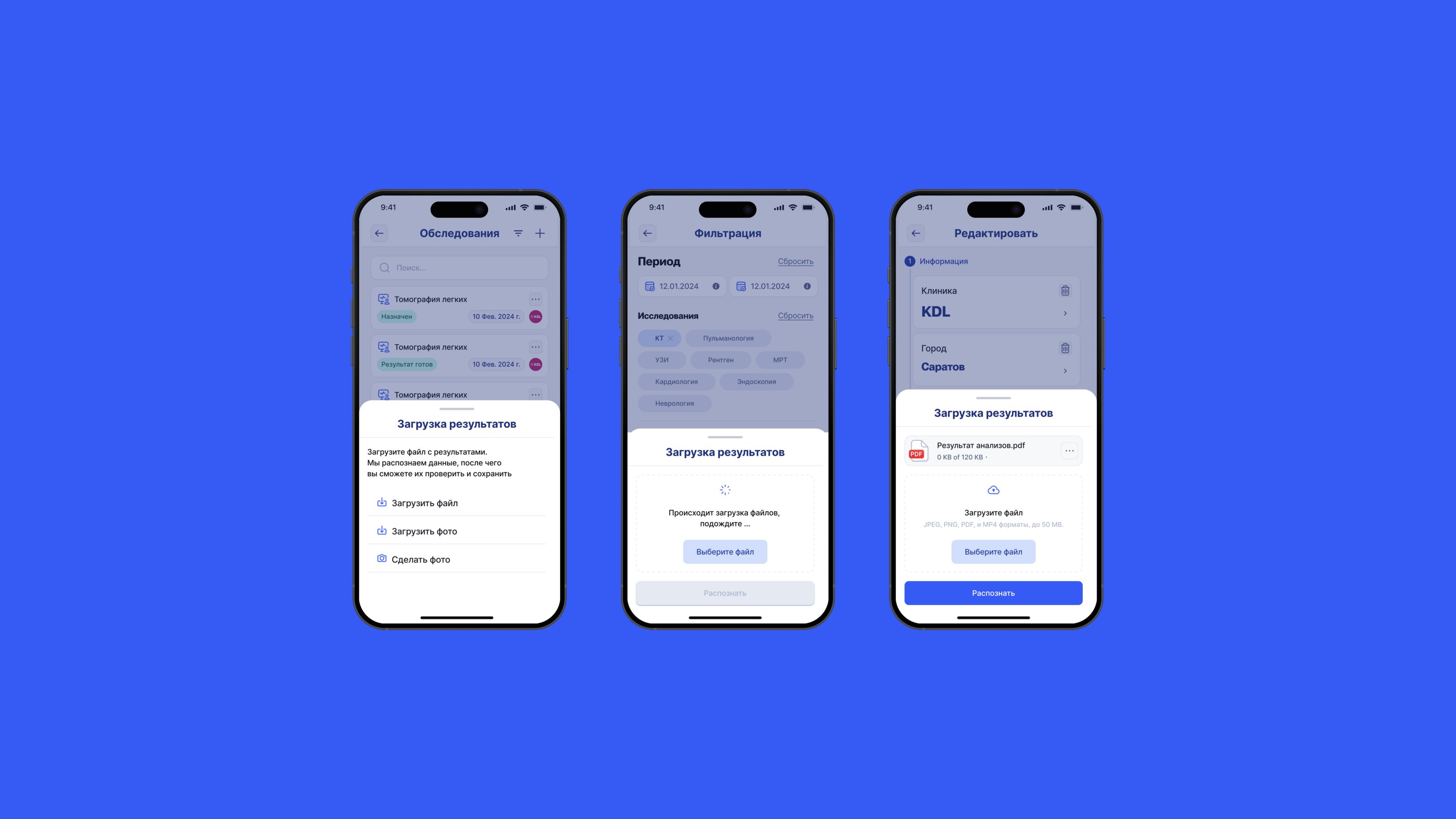
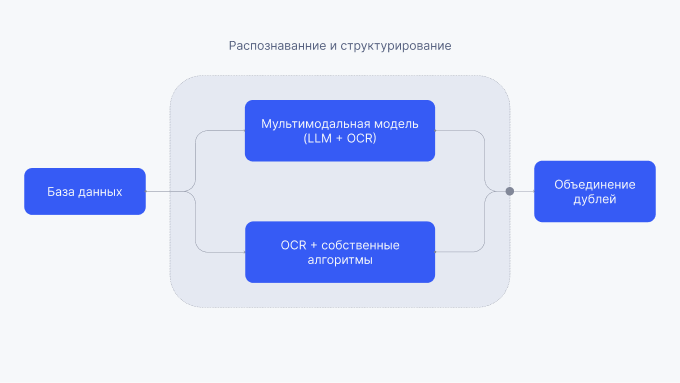
Первый этап — формирование базы данных. Затем — распознавание и структурирование данных с помощью мультимодальной модели и параллельно с помощью OCR и собственных алгоритмов. Далее — идентификация биомаркеров и объединение дублей.
Сбор базы данных биомаркеров, единиц измерений и референсных значений
⠀
Для корректной работы алгоритмов распознавания и функционирования приложения в целом, нам необходимо было собрать полную и структурированную базу данных, которая включает:
— названия биомаркеров и их синонимы
— используемые единицы измерения
— коэффициенты пересчета между ними
— референсные значения (нормы)
— типы биоматериалов
Особенности, с которыми мы столкнулись:
— Референсные значения различаются по категориям пациентов
Это достаточно очевидно: нормальные показатели одного и того же биомаркера могут отличаться в зависимости от пола, возраста и других характеристик. Поэтому для каждого биомаркера мы храним несколько вариантов референснов — для разных групп.
⠀
— Разные коэффициенты пересчета для одинаковых единиц
Менее очевидная, но важная особенность — коэффициенты пересчёта между единицами измерения зависят от конкретного биомаркера.
Представьте, что вы измеряете диван, и в одном случае 1 метр — это 100 см, а в другом — 90 см. Звучит абсурдно. Но в лабораторной диагностике такое встречается довольно часто.
Например:
— для глюкозы: мг/дл х 0,0555 => ммоль/л
— для молочной кислоты: мг/дл х0,111 => ммоль/л⠀
Это значит, что нам необходимо учитывать индивидуальный коэффициент пересчета для каждого биомаркера, и хранить соответствующие данные в системе.
Собрать такую базу — уже достаточно непростая задача. У нас уже более 2000 уникальных биомаркеров, и для каждого из них нужно найти, сопоставить и проверить:
— все возможные названия биомаркеров
— синонимы
— варианты единиц измерения
— коэффициенты пересчета
— корректные референсные значения.
Откуда мы берем данные:
Для наполнения базы мы используем два основных источника:
— Парсинг сайтов крупных лабораторий — это помогает собрать нормативную и справочную информацию.
— Обработка реальных бланков — извлекаем данные с помощью наших алгоритмов распознавания.
После этого мы агрегируем всю информацию, систематизируем и проверяем на корректность. Таким образом, база данных биомаркеров строится как результат последовательной работы по сбору, сопоставлению и нормализации большого объема медицинской информации — с учетом всех нюансов единиц измерения и физиологических параметров пациентов.
Распознавание данных с помощью OCR+собственного алгоритма
Следующий этап обработки бланков — распознавание текста с изображений. Для этого мы применили OCR (оптическое распознавание символов), а также разработали собственную логику анализа и структурирования полученных данных.
Мы протестировали несколько OCR-систем, включая Yandex OCR и другие решения. В текущей версии проекта остановились на использовании Tesseract OCR.
Предобработка изображений перед распознаванием предполагает серию шагов до передачи изображения в OCR:
— Преобразование в черно-белый формат
— Это важно, потому что лаборатории часто выделяют отклонения от нормы цветом (например, красным), и такие элементы хуже распознаются.
— Повышение резкости и контрастности
— Особенно помогает в случае некачественных фото — с засветами, размытостями и низким освещением.
— Коррекция поворотов и сдвигов изображения
— OCR-системы хуже работают с текстом, если он расположен под углом, поэтому мы предварительно выравниваем бланки.
— Выделение блоков и послойное распознавание
— Вместо чтения текста по строкам мы разбиваем изображение на логические блоки и обрабатываем каждый отдельно. Это помогает отличать биомаркеры от вспомогательных подкатегорий, которые могут визуально выглядеть схожими.
Почему построчное распознавание не работает?
На первый взгляд может показаться, что достаточно просто распознавать текст построчно. Однако в реальности это не так: некоторые строки на бланках — это заголовки, подкатегории или техническая информация, которая не содержит биомаркеров. Поэтому мы реализовали систему анализа отдельных блоков, где каждый участок изображения интерпретируется в контексте: где находится биомаркер, где его значение, а где — нерелевантная информация.
Как мы извлекаем нужные данные?
После OCR мы получаем распознанный текст и координаты каждого элемента на изображении. Далее мы производим:
— Сопоставление и структурирование данных по координатам элементов.
— Поиск в базе биомаркеров и синонимов названий, которые мы распознали.
Однако на этом этапе возникает проблема: из-за большого количества синонимов и сокращений, точное текстовое совпадение не всегда находится, и система может принять уже существующий биомаркер за новый — так возникают дубли.
Чтобы решить эту проблему, мы обратились к векторному поиску. Он сопоставляет слова не по текстовому сходству, а по смысловой близости. Но в этом случае и он не сработал, так как базовые векторизаторы настроены на естественные русский и английский языки. А биомаркеры и их синонимы — это «не естественный язык» с другими правилами смыслового сходства и различия слов.
Распознавание данных с помощью OCR+LLM
Это альтернативный подход в рамках работы над системой распознавания медицинских документов, с применением мультимодальной модели (OCR + LLM)
Напомним, что изначально мы реализовали собственный алгоритм на базе OCR с надстройками для структурирования извлеченных данных. И этот метод работает, но требует разработки и поддержки достаточно сложной логики. Во втором подходе решили упростить реализацию: делегировать всю задачу распознавания и структурирования мультимодальной модели. Иными словами, мы просто отправляем файл модели вместе с промтом, описывающим желаемую структуру данных, а модель сама извлекает нужную информацию и возвращает её в заданной форме.
— Локальное исполнение. Использование облачных API-моделей исключается — по соображениям безопасности, поскольку документы могут содержать персональные данные.
— Скорость обработки. Мы ориентируемся на мгновенное распознавание: пользователь загружает бланк и сразу получает результат. Это принципиально отличает наш сервис от решений, в которых распознавание происходит в фоновом режиме с задержкой.
После серии тестов мы остановились на модели Qwen 7B. Пока мы продолжаем параллельно тестировать оба варианта — как классический OCR-подход, так и мультимодальную модель. Точность распознавания у них примерно одинаковая, но в подходе с LLM значительно меньше объем кода и логики, которую необходимо расписывать и развивать. Одновременно с этим собственный алгоритм тоже имеет преимущества — требует значительно меньше вычислительных ресурсов и прозрачен в работе.
Сейчас мы находимся в процессе выбора финального решения. Мы стремимся к тому, чтобы функции работы с медкартой, включая распознавание документов, оставались бесплатными для пользователей. Поэтому нам важно найти не только точный, но и экономичный по ресурсам алгоритм.
Точность распознавания: хотя полноценного тестирования на больших массивах данных мы еще не проводили, уже сейчас можем говорить о неплохих результатах. По текущим замерам, точность распознавания биомаркеров превышает 90%.
Методика оценки достаточно простая и прозрачная: в тестовой выборке — около 100 бланков медицинских анализов, в каждом бланке — в среднем по 20 биомаркеров. Качество бланков сильно варьируется: от аккуратных PDF с четкими таблицами до неудачных вариантов, которые демонстрировались в этой статье в начале.
Мы прогоняли эти бланки через систему распознавания, извлекали данные по каждому биомаркеру, а затем сравнили результат с реальными значениями, содержащимися в бланке. Более 90% извлеченных данных совпали с оригиналом. Этот уровень точности уже позволяет использовать систему в реальных сценариях.
Проблема обработки дублей биомаркеров
Одной из ключевых сложностей, с которой мы столкнулись в текущем этапе разработки, и которая блокирует дальнейшие процессы — работа с дубликатами биомаркеров. Как мы уже писали выше, основная задача — сопоставить распознанное значение биомаркера из бланка с уже существующими записями в базе, включая возможные синонимы. Это необходимо для корректного построения истории изменения показателей биомаркеров, и чтобы исключить создание новых биомаркеров.
Ранее мы пробовали использовать традиционный текстовый поиск, однако он с этим не справился. Стандартные методы векторного поиска также не дали приемлемых результатов. Как мы уже писали выше, базовые векторизаторы распознают естественный русский и английский языки, а биомаркеры и их синонимы воспринимаются, как «не естественный язык».
В связи с этим мы рассматриваем стратегию дообучения эмбеддинговой модели векторного поиска. Планируется использовать корпус уже собранных наименований и синонимов биомаркеров для формирования троек значений: исходный биомаркер, близкое по смыслу значение, далекое по смыслу значение. Также в планах дальнейшее дообучение векторизатора методом Contrastive Learning.
Цель — адаптировать модель под эту предметную область, чтобы она научилась различать и правильно интерпретировать медицинские термины в контексте биомаркеров. Такой подход должен существенно повысить точность сопоставления и минимизировать появление дублей.